《2021最新Java面试题全集-2021年第二版》不断更新完善!
第九章 JDBC
1:阐述JDBC操作数据库的步骤。
下面的代码以连接本机的Oracle数据库为例,演示JDBC操作数据库的步骤。
(1)加载驱动。
Class.forName("oracle.jdbc.driver.OracleDriver");
(2)创建连接。
Connection con =
DriverManager.getConnection("jdbc:oracle:thin:@localhost:1521:orcl",
"scott", "tiger");
(3)创建执行器Statement或PreparedStatement
PreparedStatement ps =
con.prepareStatement("select * from emp where sal between ? and ?");
ps.setInt(1, 1000);
ps.setInt(2, 3000);
(4)执行语句。
ResultSet rs =
ps.executeQuery();
(5)处理结果
while(rs.next()) {
System.out.println(rs.getInt("empno") + " - " +
rs.getString("ename"));
}
(6)关闭资源。
finally {
if(con != null) {
try {
con.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
关闭外部资源的顺序应该和打开的顺序相反,也就是说先关闭ResultSet、再关闭Statement、在关闭Connection。上面的代码只关闭了Connection(连接),虽然通常情况下在关闭连接时,连接上创建的语句和打开的游标也会关闭,但不能保证总是如此,因此应该按照刚才说的顺序分别关闭。
此外,第一步加载驱动在JDBC 4.0中是可以省略的,自动从类路径中加载驱动。
2:Statement和PreparedStatement有什么区别?哪个性能更好?
(1)
PreparedStatement接口代表预编译的语句,它主要的优势在于可以减少SQL的编译错误并增加SQL的安全性(减少SQL注入攻击的可能性);
(2)
PreparedStatement中的SQL语句是可以带参数的,避免了用字符串连接拼接SQL语句的麻烦和不安全;
(3)
当批量处理SQL或频繁执行相同的查询时,PreparedStatement有明显的性能上的优势,由于数据库可以将编译优化后的SQL语句缓存起来,下次执行相同结构的语句时就会很快(不用再次编译和生成执行计划)。
为了提供对存储过程的调用,JDBC API中还提供了CallableStatement接口。存储过程(Stored Procedure)是数据库中一组为了完成特定功能的SQL语句的集合,经编译后存储在数据库中,用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行它。
虽然调用存储过程会在网络开销、安全性、性能上获得很多好处,但是存在如果底层数据库发生迁移时就会有很多麻烦,因为每种数据库的存储过程在书写上存在不少的差别。
3:使用JDBC操作数据库时,如何提升读取数据的性能?如何提升更新数据的性能?
要提升读取数据的性能,可以指定通过结果集(ResultSet)对象的setFetchSize()方法指定每次抓取的记录数(典型的空间换时间策略);要提升更新数据的性能可以使用PreparedStatement语句构建批处理,将若干SQL语句置于一个批处理中执行。
4:在进行数据库编程时,连接池有什么作用?
由于创建连接和释放连接都有很大的开销,尤其是数据库服务器不在本地时,每次建立连接都需要进行TCP的三次握手,释放连接需要进行TCP四次握手,造成的开销是不可忽视的。
为了提升系统访问数据库的性能,可以事先创建若干连接置于连接池中,需要时直接从连接池获取,使用结束时归还连接池而不必关闭连接,从而避免频繁创建和释放连接所造成的开销,这是典型的用空间换取时间的策略(浪费了空间存储连接,但节省了创建和释放连接的时间)。
池化技术在Java开发中是很常见的,在使用线程时创建线程池的道理与此相同。基于Java的开源数据库连接池主要有:C3P0、Proxool、DBCP、BoneCP、Druid等。
在计算机系统中时间和空间是不可调和的矛盾,理解这一点对设计满足性能要求的算法是至关重要的。
大型网站性能优化的一个关键就是使用缓存,而缓存跟上面讲的连接池道理非常类似,也是使用空间换时间的策略。可以将热点数据置于缓存中,当用户查询这些数据时可以直接从缓存中得到,这无论如何也快过去数据库中查询。
5:JDBC中如何进行事务处理?
Connection提供了事务处理的方法,通过调用setAutoCommit(false)可以设置手动提交事务;当事务完成后用commit()显式提交事务;如果在事务处理过程中发生异常则通过rollback()进行事务回滚。
除此之外,从JDBC 3.0中还引入了Savepoint(保存点)的概念,允许通过代码设置保存点并让事务回滚到指定的保存点
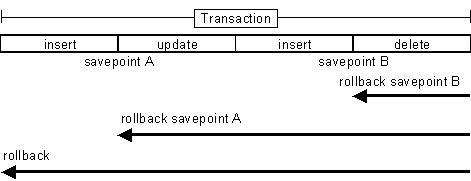
6:JDBC能否处理Blob和Clob?
Blob是指二进制大对象(Binary Large Object),而Clob是指大字符对象(Character Large Objec),因此其中Blob是为存储大的二进制数据而设计的,而Clob是为存储大的文本数据而设计的。
JDBC的PreparedStatement和ResultSet都提供了相应的方法来支持Blob和Clob操作。